Author Notes¶
This is where I’ll be documenting my own thought process and technical choices while implementing this solution, with review and conclusion once complete.
Problem Overview¶
At first glance, this looks like we’re implementing a home-baked database migrations solution. This is reinventing the wheel somewhat, as there are a wide variety of existing, mature options for handling database migrations which will be far more robust and future-proof (typically built into ORMs, e.g. SQLAlchemy in Python, Doctrine in PHP or Active Record in Ruby). However, since this is a test with fixed requirements, let’s pretend these don’t exist and we’re inventing the concept of migrations for the first time.
The approach required by the problem definition is to use the intuitive (but naive) approach of running SQL scripts in sequence, keeping track of current database state using a simple version number stored in the database itself to track the most recent script run.
Approach¶
Fictional scenario¶
To make it easier to make sensible assumptions for this use case, I decided to imagine this was being implemented by a developer who was part of a small and inexperienced team working on a web application for a furniture store.
Ths fictional dev team aren’t sure of all the requirements, yet as the store owner is still deciding various things! As such, they’re pretty much designing the database schema and application architecture on the fly - a situation where handling migrations well is essential!
Language Choice¶
All of the languages allowed by the test requirements are more than capable for this purpose. However, for a standalone script intended for execution as part of the software development lifecycle, I wanted something both:
- Feature-rich, so I’m not reinventing the wheel too much and implementing my own SQL client or pattern matching from scratch.
- Portable, so the script can be useful to devs working from different operating systems.
Now, I’ve written my fair share of Bash scripts and they have their place, but shell scripting in general doesn’t actually meet either of these requirements, so these should be avoided for anything more complex than system-specific automation tasks.
Between the three fully featured languages, Python has a clear advantage in portability, as it is available out of the box in all major Linux distributions and on macOS. It is also fairly common to see Python scripts in SDLC tooling alongside a codebase in another language, whereas choosing PHP or Ruby would be unusual unless the application itself was built in one of those languages.
Note: The requirements explicitly reference Python 2.7, which is very bad practice now as the entire community is pushing to migrate away from the 2.x branch since it is being retired in less than 10 months (January 2020). I’ve written this solution in Python 2.7 compatible code, but anyone still using it really needs to update now!
Implementation¶
MySQL database, example SQL scripts¶
I set up a MySQL database on a remote host to run these on (ignoring SDLC best practices - for now this fictional dev team are deploying changes directly to production!), and began creating SQL scripts to support the fictional scenario described above.
The scripts were then tweaked until there was a working set of migrations simulating the progressive design and creation of a handful of semi-realistic tables:
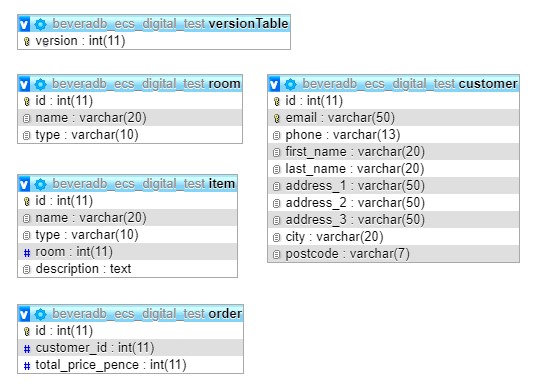
Filename inconsistency¶
To meet the test requirements, I introduced a bit of human error / inconsistency in the filenames, as if these were being created by hand by careless developers. They technically all start with a number, but these aren’t sequential (which could easily happen if the devs were attempting to collaborate in branches without good communication or any other tooling in their development process). The filename patterns aren’t consistent either, with a mix of hyphens, underscores, dots and spaces separating parts.
CLI Interface¶
As this script is designed to be executed from the command line, I wanted it to have a robust and user-friendly interface. There’s a mature and popular Python library called Click which I’ve used before, so I put together some boilerplate code and tweaked it a bit to expect the parameters defined for this test. There’s a “help” option to show usage instructions for the script, and the user is shown an informative error message if they don’t enter the correct number of arguments.
Logging¶
I’m a firm believer in robust logging for even simple scripts, so one of the first things I’ll do before implementing functionality is ensure it is easy to access well-formatted debug log entries on demand. As such, I added the click_log library, configured it and added my own custom formatter method to add timestamps to each line.
Finding SQL scripts to execute¶
To find the SQL scripts in the provided directory, we use a combination of standard library methods to iterate through all files ending with the expected “.sql” suffix and apply a regex pattern to extract the sequence number from the start of the filename (regardless of what character is after the number - we just match all numbers at the start of the string). We then cast the sequence number to an integer value to make any leading zeros irrelevant, and sort the list of SQL scripts by the sequence number to ensure they are processed in the correct order.
Connection to MySQL database¶
We connect to the MySQL database with parameters specified on the command line, using the official ‘mysql-connector-python’ library. Oddly, this library wasn’t able to function until the legacy ‘MySQL-python’ library was also installed.
Despite this connector library being the officially endorsed method of interacting with a MySQL/MariaDB database, there are several drawbacks to using this library. For one, it is reliant on a native C++ client implementation, so may require certain packages to be installed on the machine running the script, decreasing portability significantly. Additionally, I encountered a segfault when using this library from the setuptools entry point. I’ve contributed to the bug report, but this doesn’t give me a huge amount of confidence in the library.
Unfortunately, all of the alternatives I could find (e.g. PyMySQL, a pure python library) don’t support executing multiple statements at once, meaning I would be required to implement a parser of my own to split statements in the input files and process them individually. This sounds like a highly error-prone thing to implement and would likely have many edge cases, so I wanted to avoid this if possible.
Initially I attempted to re-use a single connection for the lifetime of the script, but found the connection was broken after certain operations were executed, so switched to creating and closing the connection for each migration.
Error handling¶
As the purpose of this script is to apply schema changes to a database, and in our hypothetical scenario it is likely to be used directly on the production database, I wanted it to fail quickly - if anything goes wrong, stop. For example, you don’t want to end up accidentally running one migration before the previous in the sequence, as this could have unintentionally destructive effects on production data. As such; if the database connection fails at any point, we error and exit. If a migration fails to run, we error and exit. If any exceptions are raised at any point, we error and exit, displaying a full and informative error message in the console output.
Identifying unprocessed migrations¶
Once we have a list of all of the migrations in the SQL scripts folder, we fetch the current version number from the database and filter the list of migrations to only process those with a higher version number. If the ‘versionTable’ database doesn’t exist, or doesn’t contain a version row, we set the current version to 0 and assume we’re starting out with an empty database.
Applying migrations¶
There is actually very little complexity here at all - we simply open a connection to the database, get a cursor reference, and read in the whole SQL file into a single execution call. The only thing worth noting here is that in order to execute multiple statements in a single call, the “multi” flag must be passed to the execution call. This is a feature only added to the Python MySQL connector a few years ago though, and there may be some situations where this method of executing all statements in an SQL script doesn’t work. There are a variety of alternate methods to choose from though, each with their own pros and cons.
Functional testing¶
The first thing I did as part of this project was build some example SQL scripts to be executed by this tool, so essentially the functionality was being tested multiple times at every stage of development. To make this more convenient, I added a feature to allow executing an arbitrary specified SQL file, and wrote some SQL to drop all tables which may have been created by subsequent script executions. I kept this an an additional SQL script in the migrations folder with index 0, as in the hypothetical scenario it could be useful for tearing down/recreating functional test environments if the dev team ever decided to create a proper testing pipeline.